


基于用户的协同过滤算法
核心思想
当我们的系统要向用户A进行推荐时,要先找出与用户A最相似的几个用户,再从这几个用户的点赞的帖子中预测出用户a最喜欢的几个帖子并且是用户a没有点赞过的帖子进行推荐。
接下来请跟着我的步骤来实现这个算法。
1. 相似性度量方法
首先我们要知道两个用户之间的相似度,那么这里就可以引入一个概念相似性度量方法。
杰卡德(Jaccard)相似系数
这个是用来衡量两个集合相似度的一种指标,意思是两个用户A和用户B产生交集的物品数量占两个用户所有物品数量并集的一个比例。大白话就是两个用户喜爱物品的交集越多,说明两个人的兴趣爱好越趋同。
这里给一个公式: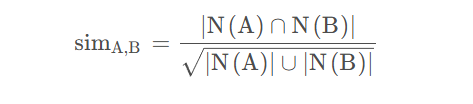
余弦相似度
在几何学当中,衡量两个向量是否相似就是看两个向量之间的夹角,如果夹角越小就说明两个向量越接近,在这里它和Jaccard公式的不同之处就在于分母的计算方式不一样,Jaccard公式的分母是用户喜爱物品的并集,而余弦相似度就是物品数量的乘积,但是我们的数据一般都是结构化数据,都是采用二维表格进行展示的,而每行或每列都是一个向量,所以我使用如下公式来计算:
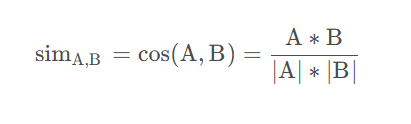
分子为两个向量的内积,分母是两个向量模长的乘积。
一般情况下我们的数据会非常多,会导致构造的矩阵会非常稀疏,即向量中的0会非常多,所以当数据量不多的时候可以采用这种方式。
皮尔逊相关系数
皮尔逊相关系数就是概率统计中学过的相关系数,取值为【-1,1】,越接近1越是正相关,越接近-1越是负相关,如果为0,则表明二者不相关。
皮尔逊相关系数的计算方法和余弦相似度的计算方式很相似,这里的公式如下:
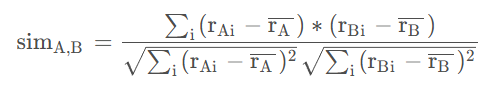
根据综合考量,最终在我的系统中选择了Jaccard公式来计算相似度。
2. 找出与用户A最相似的用户
Jaccard公式中用户A与用户B之间的相似度,是用户A和用户B共同交互过的物品的数量除以根号下(用户A的喜爱过的物品总数*用户B喜爱过的物品总数)。
根据Jaccard公式,我们需要两个前置条件,分别是每2个用户之间共同交互过的物品数量,每个用户所交互过的物品总数量。
2.1 求每2个用户之间共同交互过的物品数量
正常的思路就是先得到每个用户交互过的物品,然后再建立倒排表,来表示每个物品被哪些用户交互过。
首先要得到第一个前置条件(每2个用户之间共同交互过的物品数量),我们首先计算出两个Map:
(1)Map<String,Set<String>>userToArticles = new HashMap<>();
这个Map存的是用户ID所对应的一个交互过的物品id的Set集合。
(2)Map<String, Integer> nums = new HashMap<>();
这个Map存的是每个用户ID对应的该用户交互过的物品总数。
以下给出实现代码:
Map<String, Set<String>> userToArticles = new HashMap<>();
Map<String, Integer> num = new HashMap<>();
for(UserInfo user : userInfoList) {
Set<String> articleIds = new HashSet<>();
List<String> objectIds = mapper.selectByUserId(user.getUserId());
articleIds.addAll(objectIds);
userToArticles.put(user.getUserId(),articleIds);
num.put(user.getUserId(),articleIds.size());
}然后我再根据第一个Map来建立倒排表,表示每个物品被哪些用户交互过。
具体逻辑就是,遍历userToArticles 这个Map的每个键值对,在嵌套内循环遍历每个键值对中的Set<String>,也就是用户交互过的物品集合,将每个遍历到的物品和当前对应的键(也就是当前遍历到的用户)存进倒排表,就是这样一个Map,表示每个物品所对应的交互过这个物品的用户的集合,Map<String, Set<String>> itemToUsers。
以下给出实现代码:
public static Map<String, Set<String>> getItemToUsers(Map<String, Set<String>> userToItems) {
Map<String, Set<String>> ItemToUsers = new HashMap<>();
for (Map.Entry<String, Set<String>> entry : userToItems.entrySet()) {
String userId = entry.getKey();
Set<String> articleIds = entry.getValue();
for (String articleId : articleIds) {
//如果当前文章对应的用户集合中没有用户,就新建一个Set再把当前用户加进去,如果有的话就之间加进去
Set<String> users = ItemToUsers.getOrDefault(articleId, new HashSet<>());
users.add(userId);
ItemToUsers.put(articleId, users);
}
}
return ItemToUsers;
}求出倒排表之后,接下来我们就可以计算每2个用户之间共同交互过的物品数量(协同过滤矩阵),
Map<String, Map<String, Integer>> CFMatrix = new HashMap<>();
# String表示当前用户,对应的Map<String, Integer>表示其他各个用户以及与当前用户的共同交互过的物品的数量具体步骤是:
(1)遍历这个倒排表,嵌套内循环遍历每个物品对应的用户集合的每个用户。
(2)对于遍历到的每个用户,通过遍历其他所有用户,将当前用户与其他用户的共同交互物品数加一。
以下给出实现代码:
public static Map<String, Map<String, Integer>> getCFMatrix( Map<String, Set<String>> itemToUsers) {
Map<String, Map<String, Integer>> CFMatrix = new HashMap<>();
logger.info("开始构建协同过滤矩阵....");
// 遍历所有的物品,统计用户两两之间交互的物品数
for (Map.Entry<String, Set<String>> entry : itemToUsers.entrySet()) {
String item = entry.getKey();
Set<String> users = entry.getValue();
// 首先统计每个用户交互的物品个数
for (String u : users) {//遍历所有该博客对应的交互过的用户
// 统计每个用户与其它用户共同交互的物品个数
if (!CFMatrix.containsKey(u)) {
CFMatrix.put(u, new HashMap<>());
}
for (String v : users) {//再次遍历所有用户,对不是u的其他用户进行操作
if (!v.equals(u)) {
if (!CFMatrix.get(u).containsKey(v)) {
CFMatrix.get(u).put(v, 0);
}
CFMatrix.get(u).put(v, CFMatrix.get(u).get(v) + 1);
}
}
}
}
return CFMatrix;
}我们现在就能得到协同过滤矩阵的Map。
2.2 求每个用户所交互过的物品总数量
这一步就需要我们上面求得协同过滤矩阵CFMatrix和每个用户所交互的物品总数求相似度,然后就要运用到我们最开始说的jaccard公式。
以下给出实现代码:
public static Map<String, Map<String, Double>> getSimMatrix(Map<String, Map<String, Integer>> CFMatrix, Map<String, Integer> num) {
Map<String, Map<String, Double>> sim =new HashMap<>();
logger.info("构建用户相似度矩阵....");
for (Map.Entry<String, Map<String, Integer>> entry : CFMatrix.entrySet()) {//遍历协同过滤矩阵,遍历每个键值对
String u = entry.getKey();
Map<String, Integer> otherUser = entry.getValue();
for (Map.Entry<String, Integer> userScore : otherUser.entrySet()) {
String v = userScore.getKey();
int score = userScore.getValue();
if(!sim.containsKey(u))
{
sim.put(u,new HashMap<>());
}
sim.get(u).put(v, CFMatrix.get(u).get(v) / Math.sqrt(num.get(u) * num.get(v)));
}
}
return sim;
}我们现在得到的Map(Map<String, Map<String, Double>> sim)结果是当前用户对应的其他用户以及其他用户与当前用户的相似度。
2.3 物品推荐
这一步可以根据你们系统实际出发,这里就以我实际应用的系统来举例。
在我的系统中,我只取前20个用户,然后遍历这些用户交互过的物品,但是被推荐用户还没有交互过的物品进行打分。分数的计算就是(用户相似度*物品分数),物品分数根据你们系统来设置权重,我这里设置交互过的物品计分为1。
这里每个物品的推荐度就是被交互过的用户相似度之和。
以下给出实现代码:
public static Set<String> recommendForUser(Map<String, Map<String, Double>> sim,
Map<String, Set<String>> valUserItem,
int K, int N, String targetUser) {
logger.info("给用户进行推荐....");
Map<String, Double> itemRank = new HashMap<>();
if (valUserItem.containsKey(targetUser)) {
// 按照相似度进行排序,然后取前 K 个
List<Map.Entry<String, Double>> sortedSim = new ArrayList<>(sim.get(targetUser).entrySet());
Collections.sort(sortedSim, new Comparator<Map.Entry<String, Double>>() {
public int compare(Map.Entry<String, Double> o1, Map.Entry<String, Double> o2) {
return Double.compare(o2.getValue(), o1.getValue());
}
});
logger.info("检查对相似度矩阵排序后的矩阵");
for (Map.Entry<String, Double> entry : sortedSim) {
String item = entry.getKey();
Double similarity = entry.getValue();
logger.info("用户 " + item + ", 相似度: " + similarity);
}
for (int i = 0; i < K; i++) {
//前k个相似度高的用户
if (i >= sortedSim.size())
break;
String similarUser = sortedSim.get(i).getKey();
double score = sortedSim.get(i).getValue();
// 找出相似用户中有交互的物品,但当前用户并未交互过的物品进行推荐
for (String item : valUserItem.get(similarUser)) {
if (valUserItem.get(targetUser).contains(item))//如果用户已经对该物品交互过,就不用再推荐
continue;
itemRank.put(item, itemRank.getOrDefault(item, 0.0) + score);
//这里就得到的推荐候选的一个集合
}
}
}
// 根据评分进行排序,取排名靠前的 N 个物品作为推荐列表
List<Map.Entry<String, Double>> topNItems = new ArrayList<>(itemRank.entrySet());
Collections.sort(topNItems, new Comparator<Map.Entry<String, Double>>() {
public int compare(Map.Entry<String, Double> o1, Map.Entry<String, Double> o2) {
return Double.compare(o2.getValue(), o1.getValue());
}
});
Set<String> recommendedItems = new HashSet<>();
for (int i = 0; i < Math.min(N, topNItems.size()); i++) {
recommendedItems.add(topNItems.get(i).getKey());
}
return recommendedItems;
}到这里,我们就能得到被推荐物品的id集合,Set<String> articleIds。
结语
一入JAVA,深似海啊。
这个方法有个缺点,在项目上线初期即还未收集到足够的用户信息时,无法向用户提供准确的预测。对于新用户来说,因为新用户还未与系统中的物品进行过交互,所以页无法向新用户进行推荐。
- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝